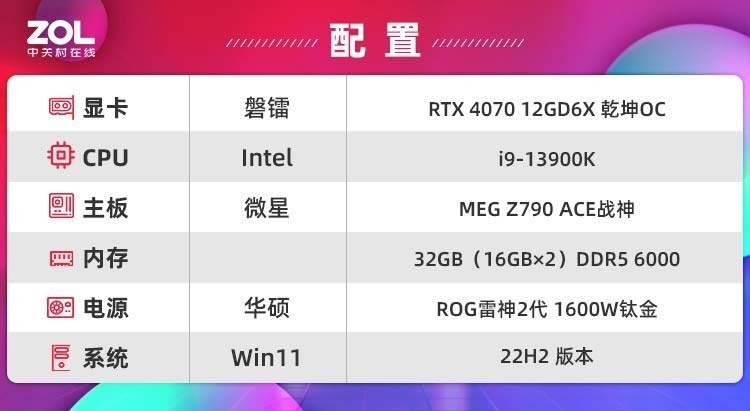
截止目前RTX 4060已经发布,RTX 40系也终于完成了从60-90级别的布局。而70级产品价格和性能都做到了较好的平衡,是3A游戏玩家的不二之选,今天带来的评测为——磐镭RTX 4070 12GD6X 乾坤OC显卡。

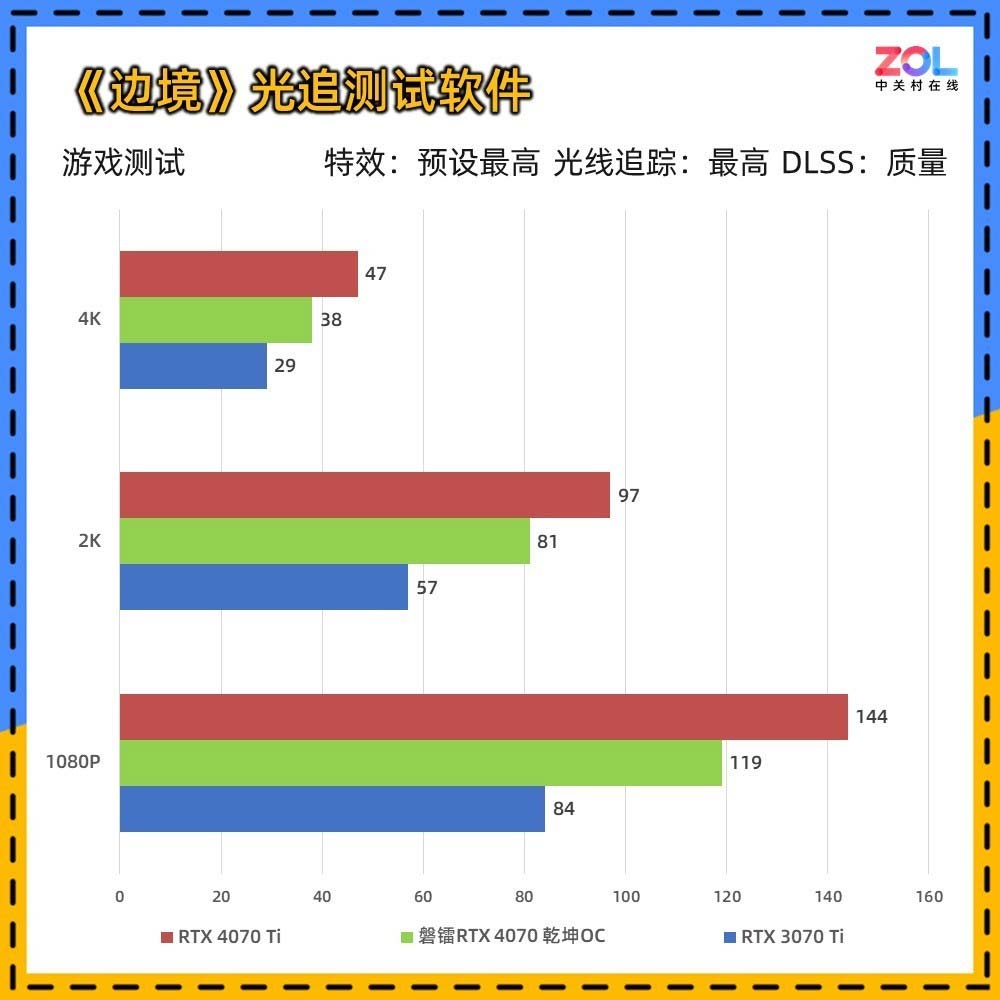
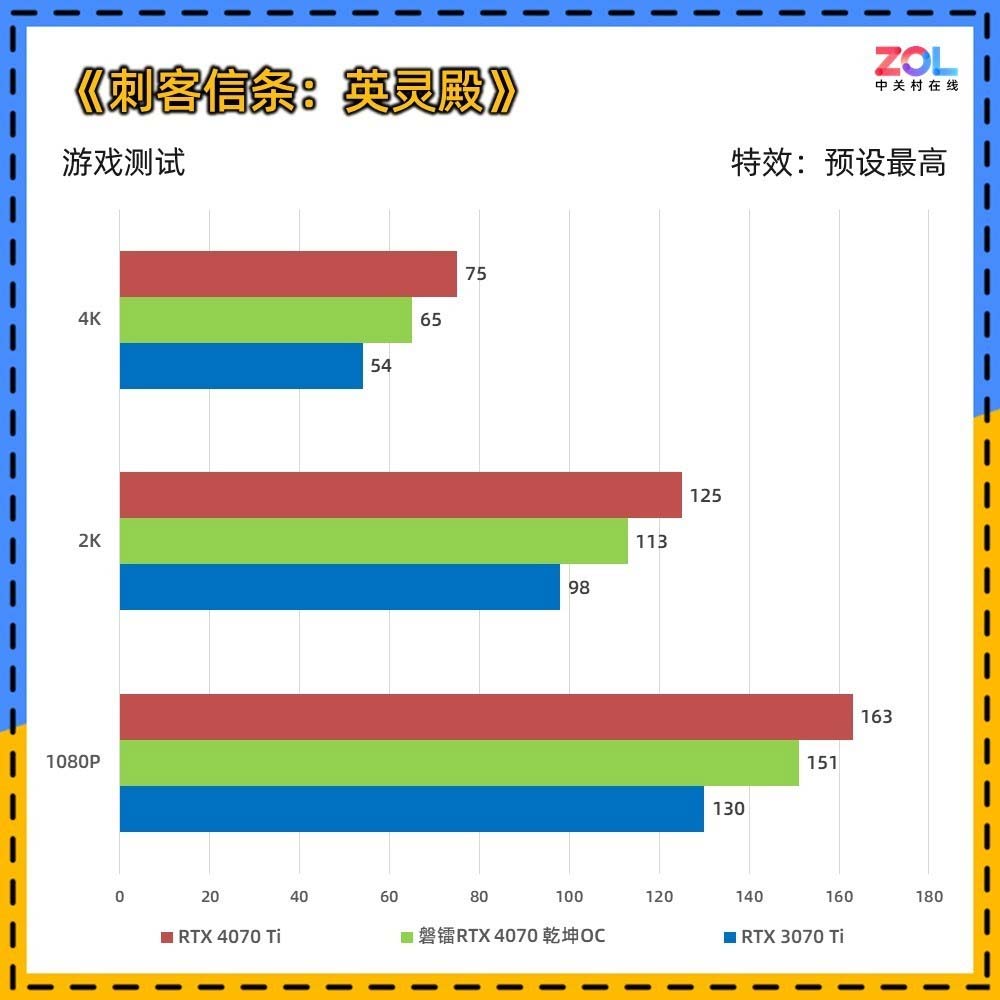
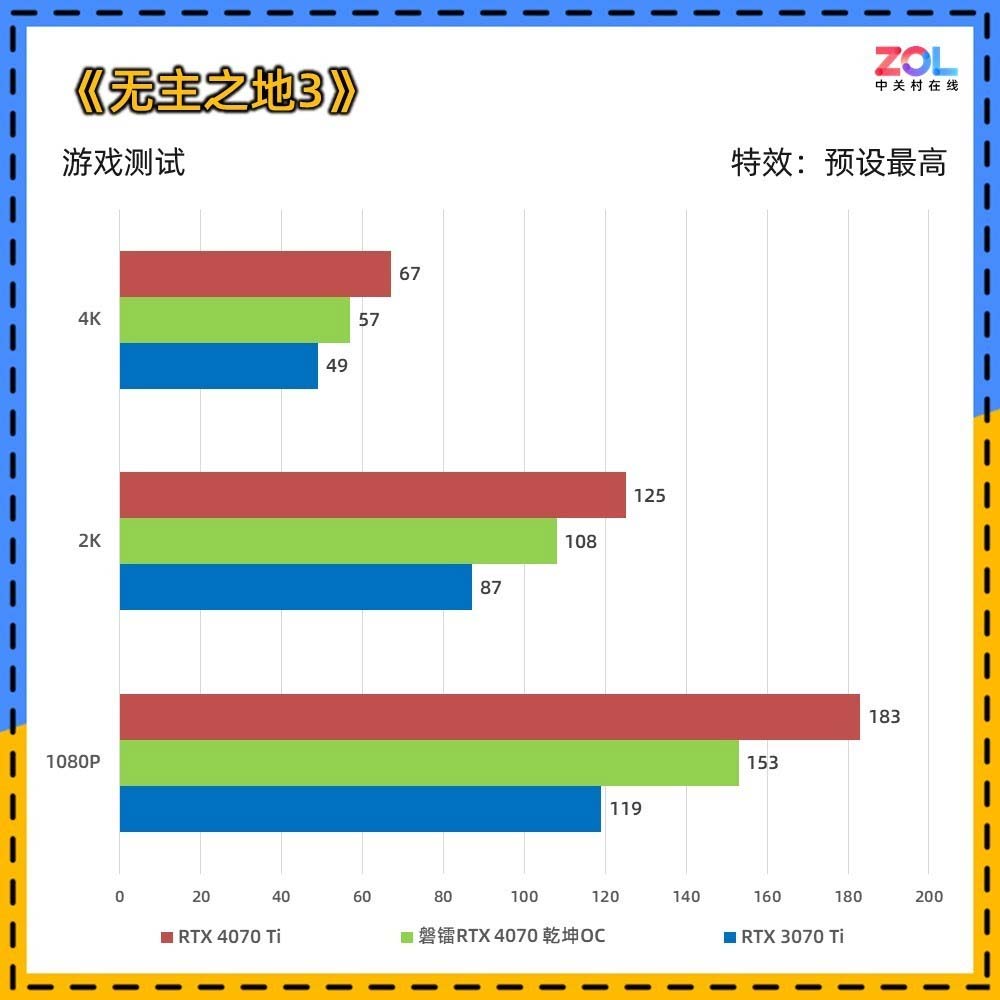
RTX 4070显卡定位在开启光追和DLSS的情况下,3A游戏达到2K百帧及以上的水准。它相比RTX 3070 Ti性能提升20%左右,与RTX 3080不分伯仲,并且在光追及DLSS方面要领先RTX 30系显卡。
磐镭这张RTX 4070虽然姗姗来迟,但好事多磨,全新的乾坤系列,让第一次拿到显卡的我相当震惊,相信也颠覆了广大网友对磐镭的印象。下面我们先来看看这款磐镭RTX 4070 乾坤OC的外观及设计理念。
磐镭RTX 4070 乾坤OC概览
首先介绍一下磐镭RTX 40系显卡的系列构成。本次评测的乾坤(TAICHI)系列定位中端,在性能与价格之间取平衡点,既有不俗的性能,又在外观上有一定的创意,适合于绝大多数游戏用户。在其系列之下还有定位高性价比的鳞甲(ARMOUR)系列,保障标准性能的同时,简化设计。
而在乾坤(TAICHI)系列之上,更有神秘的旗舰烛龙(FIERY)系列,目前尚未推出,但根据官方介绍,仍有令人惊喜的设计,并且进一步加强了散热效能,大家可以期待一下。毕竟这张乾坤系列显卡的设计水准,已经完全超出了大家的预期。
磐镭RTX 4070 乾坤OC显卡的包装正面为产品渲染图,并且显卡背景已经很明显的表达了其像素风的设计理念。
有意思的是,磐镭RTX 4070 乾坤OC显卡采用了一次性封装,仪式感极强。也保证了每名玩家拿到手的都是新卡无拆封过的。
配件中除了常规的说明书保修卡外,还有一张会员卡和螺丝刀,并且贴心的准备了两颗机箱挡板螺丝。
磐镭RTX 4070 乾坤OC整体采用蓝白拼色设计,清新淡雅。其实相较官方解释的像素风格,个人更倾向于它是,马赛克风格与像素风的合体。
虽然两种风格感觉大体相似,但像素风更接近电子游戏和传统8位视频游戏的视觉风格,经典作品有《超级马里奥》、《魂斗罗》等。而直至目前,像素风游戏仍然以强游戏性和低配置需求,拥有大批忠实玩家。














从上至下依次为超级画质/光追超级/光追过载。可以看到光追过载相比光追超级更贴近于真实效果。它模拟了真实的光线路径,其实相比之前的光线追踪模拟了更多光线在不同表面的反射,完整的计算出了场景的真实光照,避免了上一代光追中出现“死黑”的情况。
这也是NVIDIA致力于打造的下一代光追场景,但是截止目前它对硬件计算的需求太过庞大,即便是旗舰显卡,也无法在4K分辨率下流畅运行。
Stable Diffusion AI绘画测试
除了游戏之外,AI也是目前大火的领域,尤其以Stable Diffusion为最,现在很多AI生成的图片完全能够以假乱真,下面我们也来测试一下RTX 4070在这方面的表现。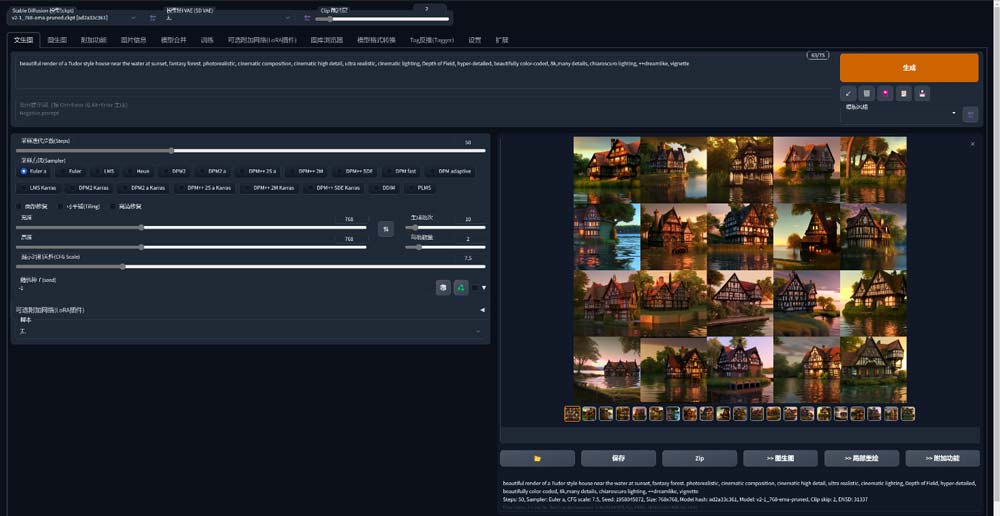
Stable Diffusion可以说几乎没有门槛,但本地部署的繁琐程度劝退了很多用户。上图为操作界面用户可根据自己想要生成的图片细节丰富关键词。
按照NVIDIA提供的关键词,我们生成了10批,共20张图片,上面挑选了两幅细节比较合理的进行了展示。
RTX 4070运算时间 2m24.79s 约合 7.2秒一张图
RTX 3070 Ti运算时间2m54.34s 约合 8.7秒一张图
Stable Diffusion对于显卡的要求比较高,这就需要显卡拥有较强的Tensor算力。
另外它对于显存的要求非常高,如果有条件的话尽量选择大容量显存的显卡。
我们对比了RTX 4070和RTX 3070 Ti在相同设置下的运算时间,两款显卡在生成20张图片的时间差距为30秒,差距还是比较大的。
另外我们也测试了使用CPU,在相同设置下生成图片,但如图片所示,保守估计需要3小时30分左右。
并且在使用CPU渲染时经常会提示内存不足,不过我们的测试平台为最旗舰的i9-13900K,内存为D5 7200MHz 32G(16G*2),可见一款趁手的显卡对于追赶潮流也是很重要的。
AV1编码测试
本次AV1编码测试选择了剪映专业版,它可以输出H.264/HEVC/AV1三种编码格式的视频。
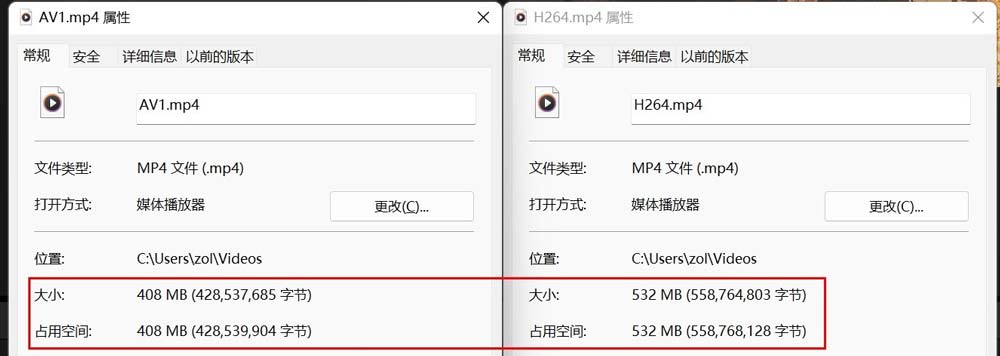
剪映专业版目前自带AV1编码输出,在实际测试中,我们导出一段1分钟左右的视频。可以看到两个文件容量相差103MB。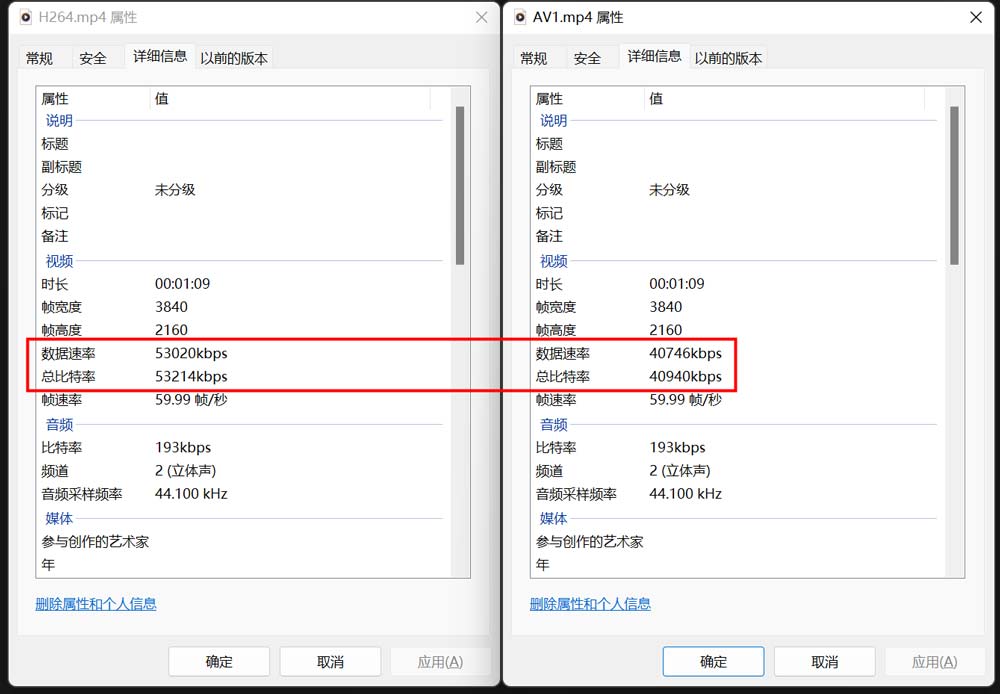
由于AV1编码特性,生成文件的比特率更低,但视频清晰度则完全相同。所以如果生成同比特率,同容量的文件,AV1将会更清晰。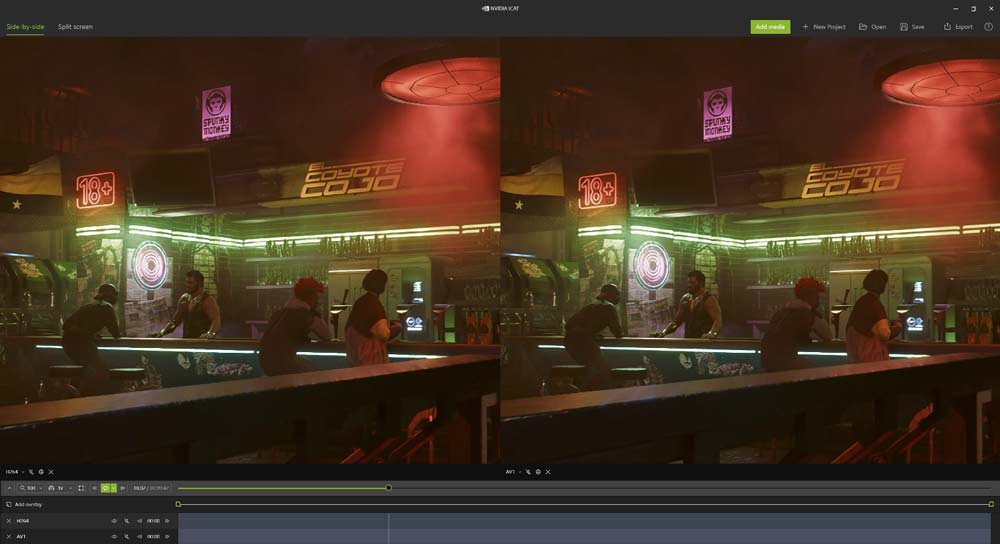
我们通过NVIDIA ICAT来进行两段视频的画面对比,图中左侧为H.264编码,右侧为AV1编码。在100%的细节对比中,几乎看不出任何区别。
RTX VSR(RTX Video Super Resolution)测试
目前RTX VSR(RTX Video Super Resolution)已经在部分浏览器中进行测试,首先玩家需要更新到NVIDIA最新驱动,在NVIDIA控制面板中的【调整视频图像设置】可以看到最新的RTX 视频增强超分辨率。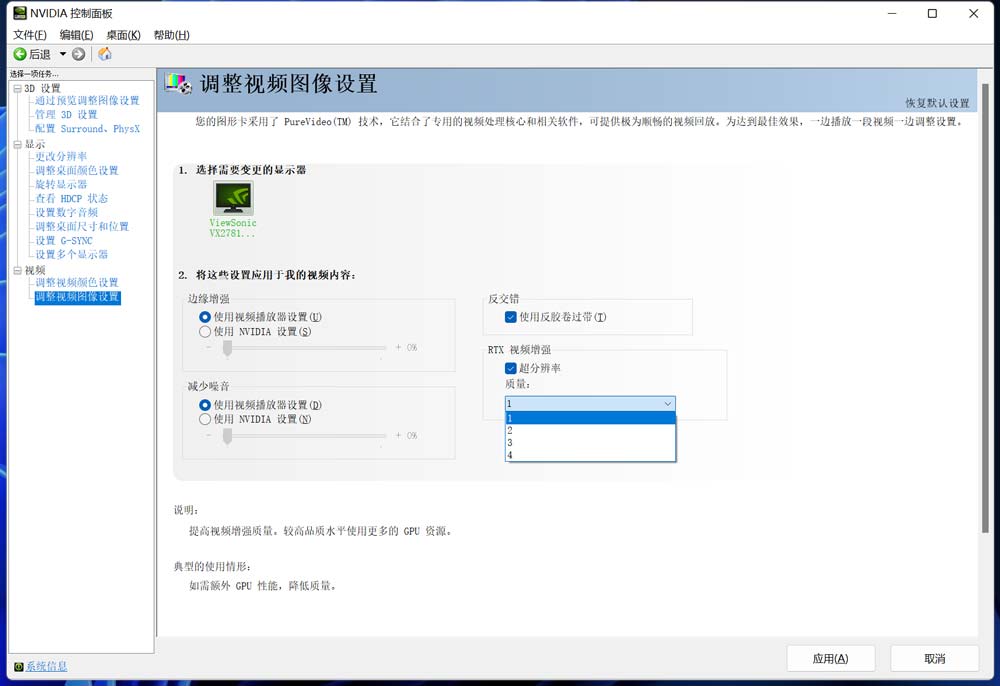
RTX VSR是 AI 图像处理的突破,它超越了传统的边缘检测和特征锐化技术,极大地提升直播视频内容的质量。
开启RTX VSR不仅需要最新版驱动,还需要使用RTX 40或30系列GPU,并且几乎适用于Google Chrome和Microsoft Edge浏览器中的所有视频内容(浏览器也需要更新到最新版本)。
开启后,目前已知的打开YouTube或者B站,都可以享受到RTX VSR效果的加成。
如果不确定,在全屏播放视频时,可以打开任务管理器,看到GPU负载增加,即为开启成功。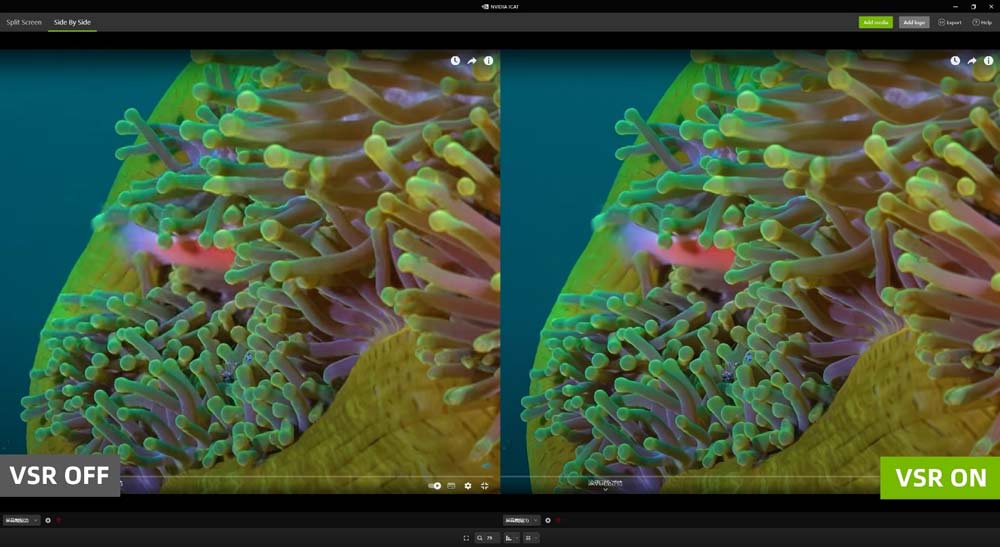
我们打开YouTube随意观看视频,在打开RTX VSR后,可以清晰明显的看到水下珊瑚的质量明显提高,边缘更为清晰,并且极大减少了失真现象。
温度及功耗测试
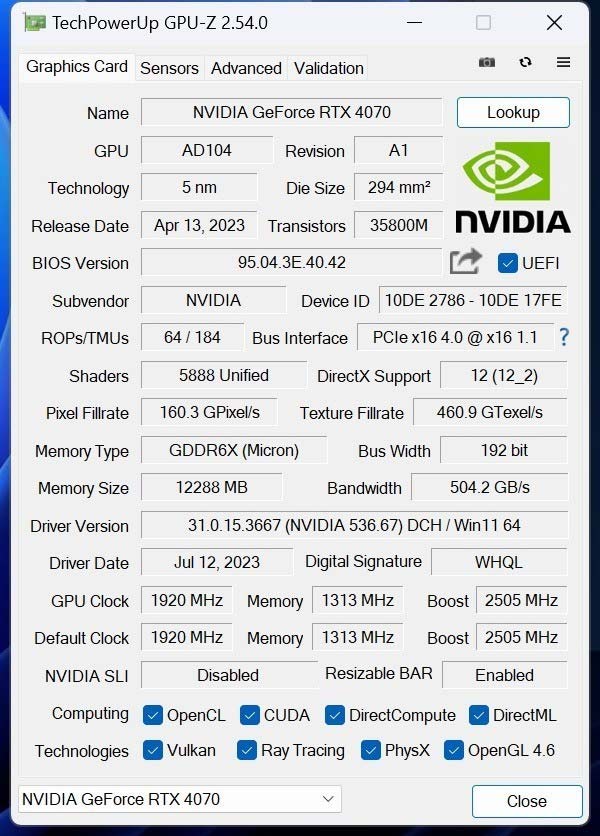
功耗测试中,我们选择FurMark软件进行拷机测试,并采用GPU-Z检测温度,功耗仅计算显卡自身。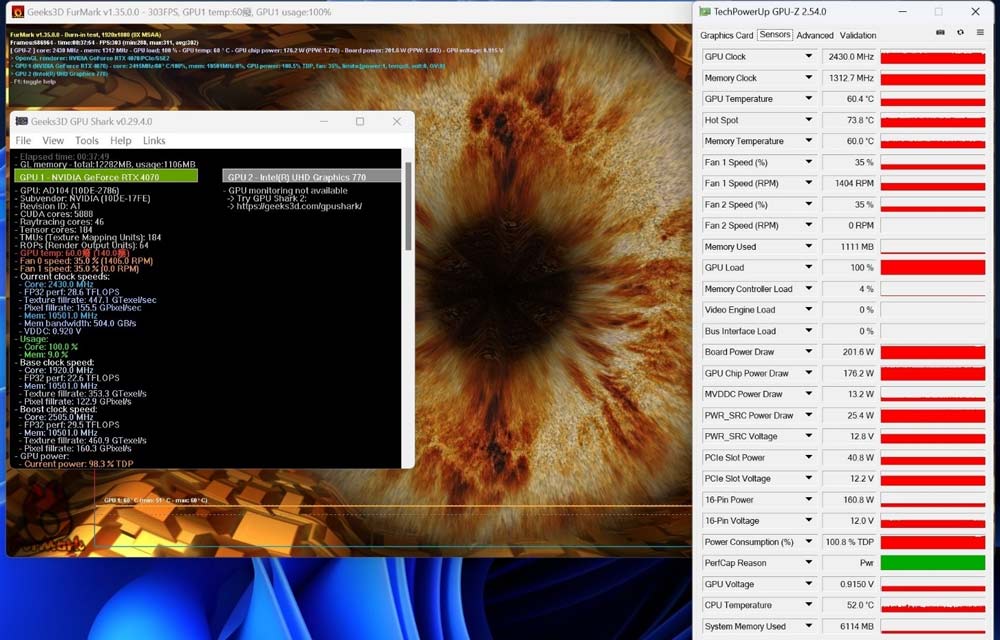
可以看到磐镭RTX 4070 乾坤OC这张显卡对于温度的控制非常不错,通过40分钟左右的拷机测试,温度一直控制在61℃左右,热点温度在74℃左右。
游戏动态功耗测试
值得一提的是,本次我们在拷机测试中最大板载功耗为200W左右,TDP达到了100%。但在实际游戏测试中,大部分3A游戏均低于额定功耗。
所以在实际的使用过程中,由于不同游戏负载不同,GPU的实际功耗是动态变化的,类似于FPS随时间的变化,RTX 40系列很难触及功耗墙。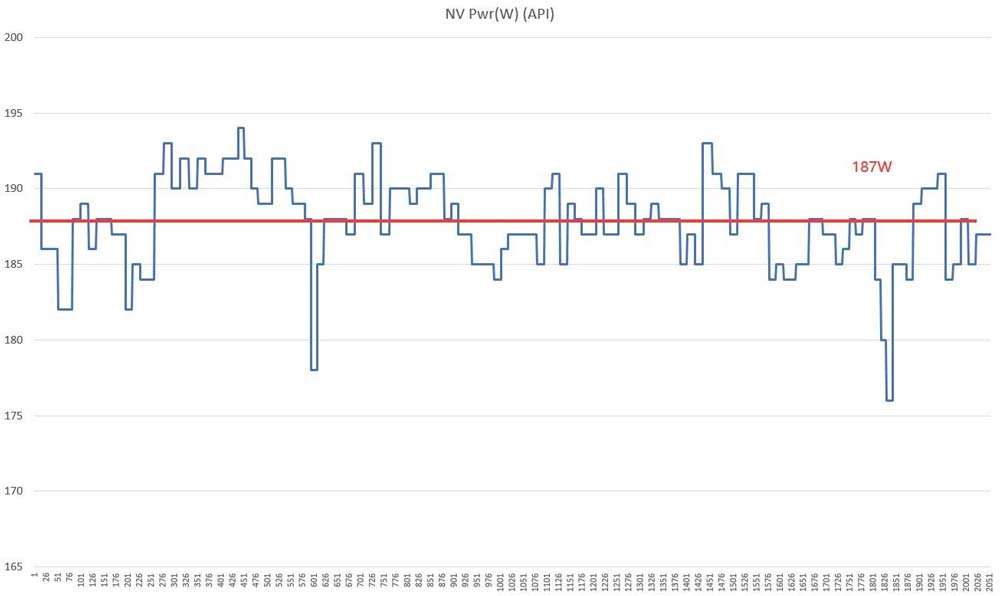
磐镭RTX 4070 乾坤OC 3A游戏平均功耗为187W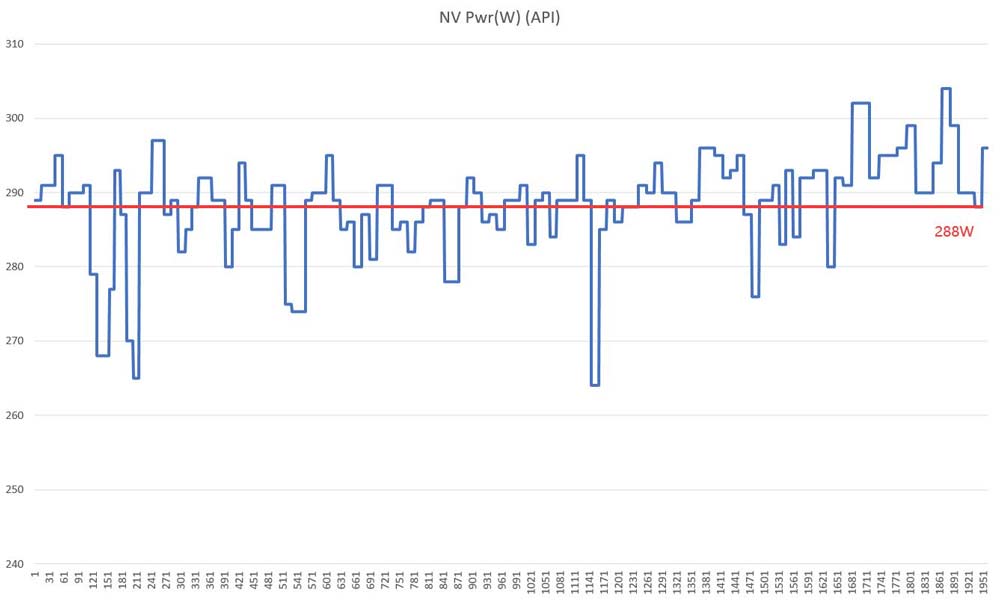
RTX 3070 Ti 3A游戏平均功耗为288W
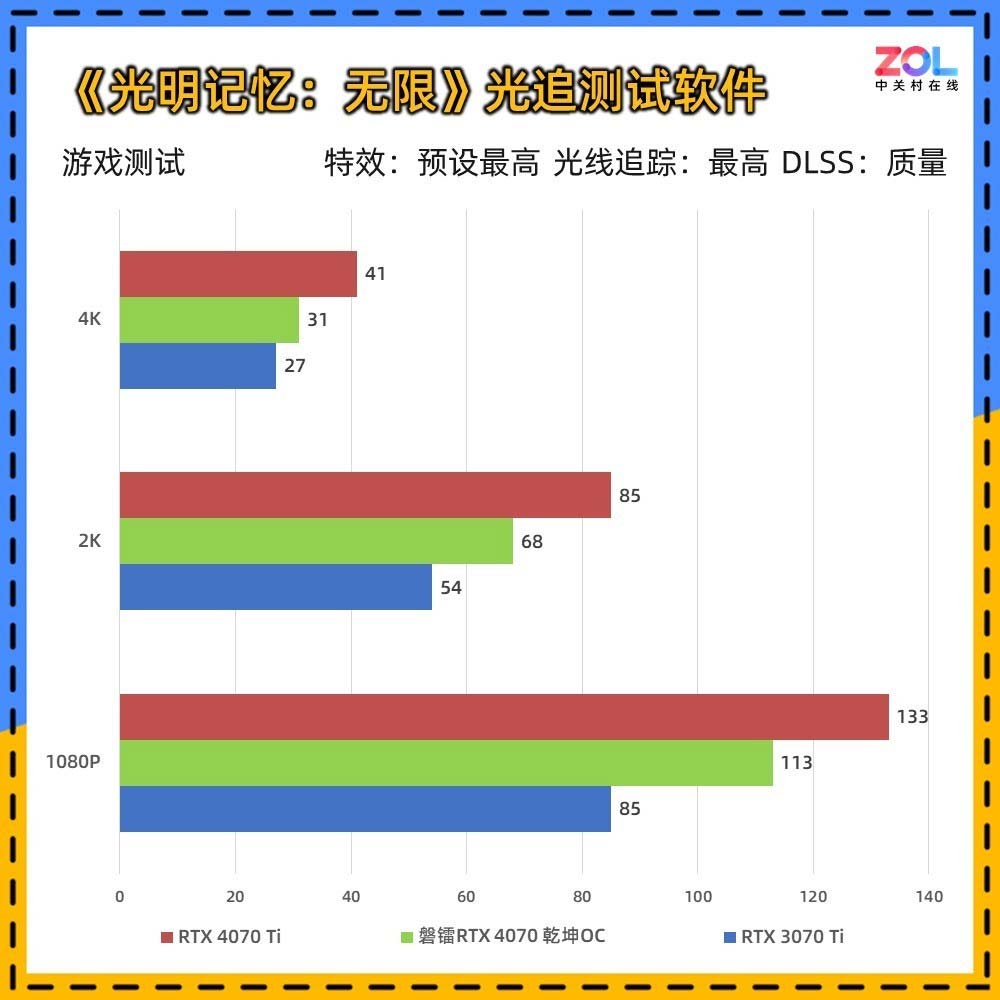
在实际的游戏功耗测试中,我们选择《光明记忆:无限》自带benchmark,画面设置为光追最高、4K分辨率,来强行拉满两张显卡的性能极限,检测我们实际应用场景的功耗。
可以看到两款显卡虽然均为70级别,但磐镭RTX 4070 乾坤OC平均功耗为187W,而RTX 3070 Ti则是288W,低了100W左右,这的确是一个惊人的成绩。
壶中日月 方寸乾坤
磐镭这款RTX 4070 乾坤OC显卡整体测试下来,给我最大的感觉在于外观设计上的惊喜,毕竟RTX 4070作为一张5月份发布的显卡,性能大家已经知悉。
这张显卡整体融合了像素风和马赛克风格,整体看起来清新淡雅,但却内藏玄机。尤其是卡身设计中隐藏的“乾坤”概念,不止停留在系列名称上。

性能上,RTX 4070可以在3A游戏中,2K分辨率下达到百帧的成绩。至于4K,目前大部分独立游戏或者网游也都没有问题。
在整体RTX 40系显卡中,最有意义的升级在于功耗下降。中端显卡采用单8pin供电,这在RTX 30系中还挺让人奢望的。而且同级别产品功耗下降100W,综合性能提升20%左右,的确称得上升级迭代。
目前磐镭RTX 4070 乾坤OC的日常售价为4599元,参与满减最终到手4499元。相比官方建议的4799低了300元,还是非常实惠的,而且它本身的设计,有兴趣的朋友不妨看看。
出处:https://diy.zol.com.cn/826/8263654.html



